Visualizing Binary Search Trees with Claude 3.5
While reviewing the LevelDB source code, I came across the skip list implementation. The skip list paper mentioned binary search trees, which inspired me to create a visualization for binary search trees. So, I started to leverage Claude 3.5 to help me implement it.
Here's the final result that you can experience:
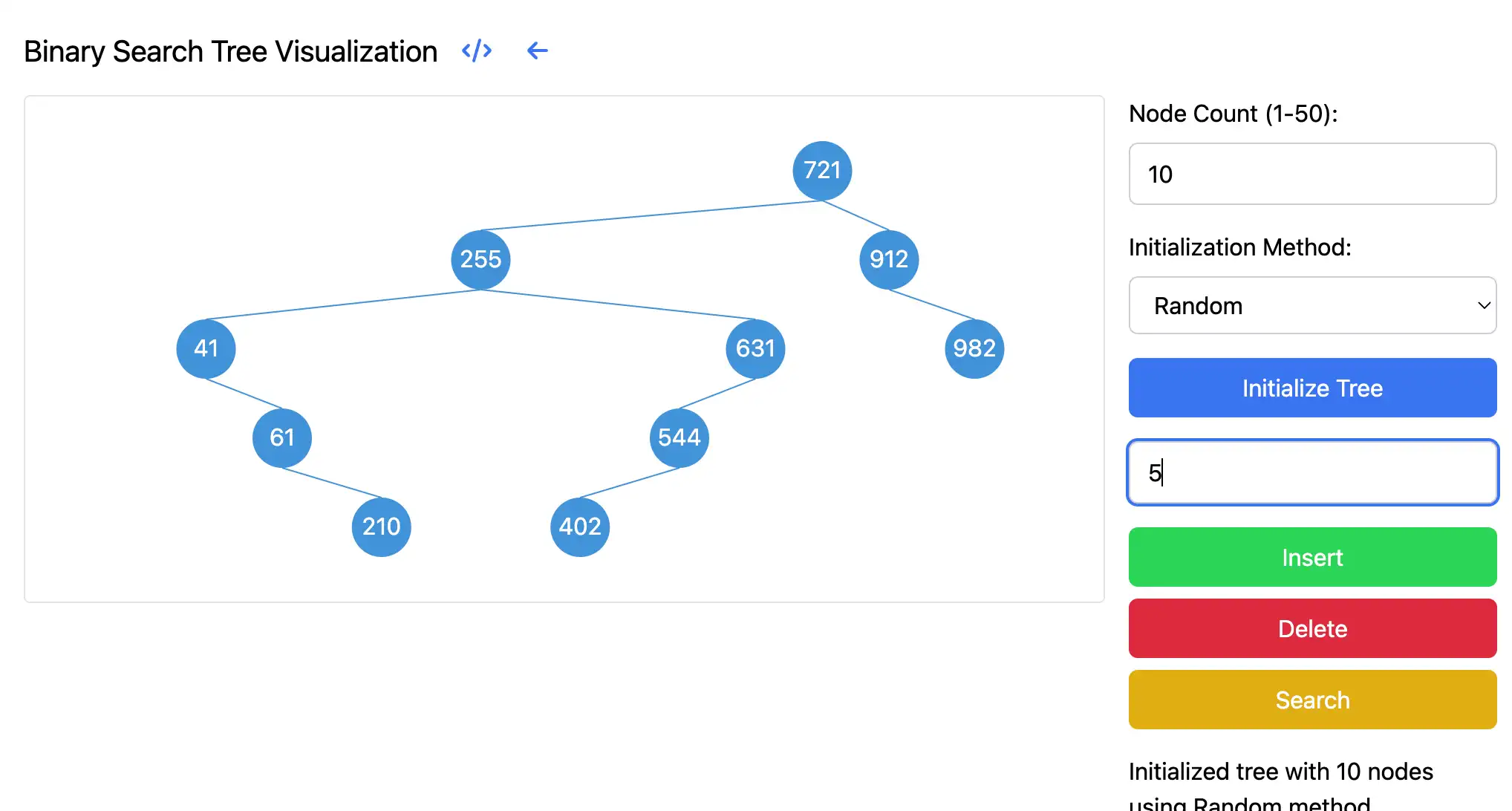
Simple Version
Claude 3.5 has a good overall understanding, and based on previous experience, the initial prompt can be quite simple as Claude 3.5 has a lot of prior knowledge. My prompt was as follows:
I want to implement a visualization of a binary search tree using React and Tailwind. Given a key, generate a binary tree that supports insert, delete, and search operations.
Additionally, since other parts of the project used headlessui, to maintain style consistency and avoid introducing too many UI components, I told Claude to continue using headlessui. The first version was quickly completed, but the page was empty with just a blank area. So I asked again:
I want to see a visualization of a binary tree, but currently there's nothing.
Claude fixed some issues, and after refreshing the page, I saw a binary tree structure. However, when I entered a number and clicked to insert a node, the entire page became empty again. I continued to ask:
Now after inputting a number and clicking insert, the entire tree disappears
Claude 3.5 admitted this was a serious bug, showing its willingness to acknowledge mistakes. It then provided a fix, mainly ensuring that the tree visualization is updated after inserting a new node.
After these few rounds of dialogue, we had an initial version. It now supports insert, delete, and search operations in the binary search tree and provides a visual representation of the tree nodes. Here's an image of this version:
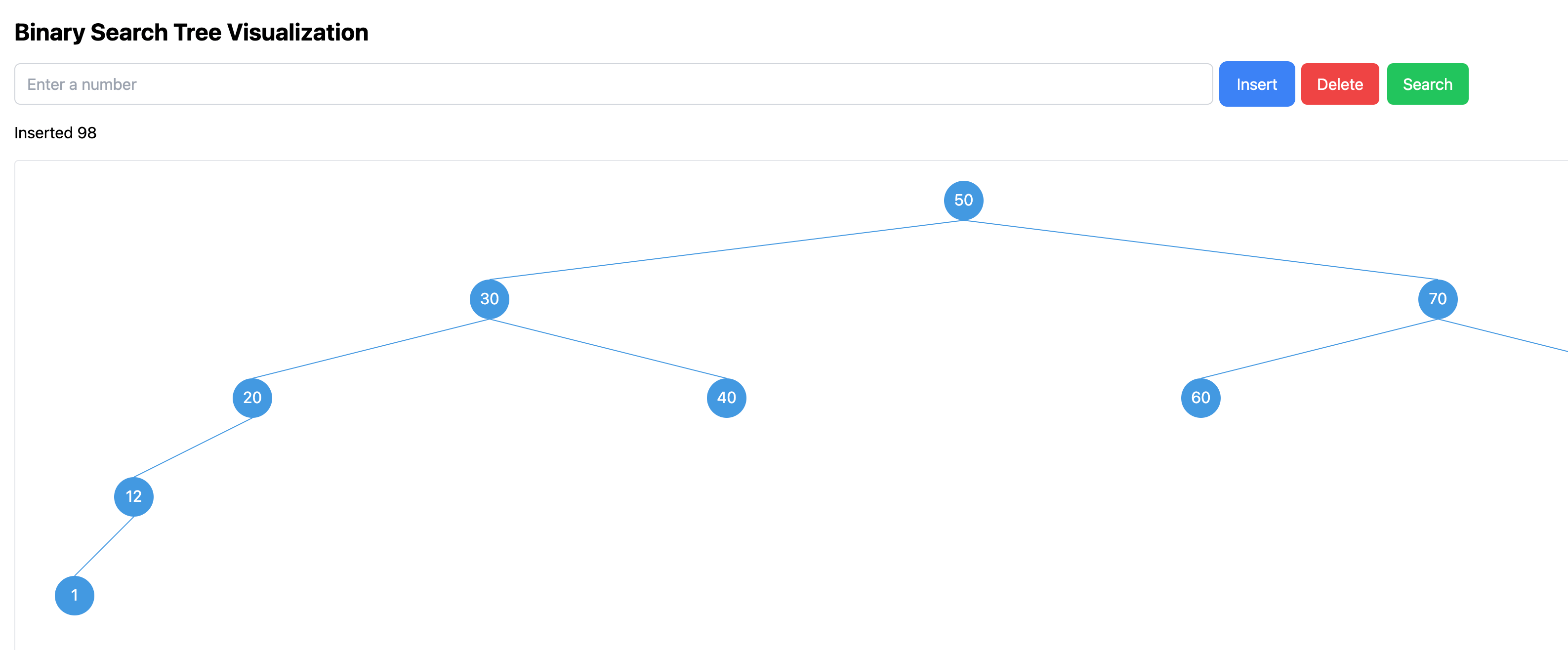
Tree Layout Optimization
However, the tree layout in this version still had some issues. After inserting several nodes, as the tree depth increased slightly, it became extremely wide, requiring scrolling to see the entire tree on the screen. I wanted a tree layout that could be more compact, displaying more nodes on the screen for a better experience. This involved many rounds of dialogue, constantly adjusting various details, and was quite a winding process.
Initially, my own thinking was not quite right. I considered using the node layout algorithm from the heap visualization. The prompt was as follows:
After insertion, the tree width is very wide, making it difficult to read. Here's an idea for you to appropriately draw the tree structure.
Each time a new layer is added, you should ensure that the bottom layer nodes are very close, with a gap of one node width. Then calculate the spacing between nodes for each layer upwards. After that, draw the entire tree based on these spacings.
Claude, as usual, flattered me and then implemented based on this idea. The effect was not good because the binary search tree might be sparse at each level, causing the spacing between middle-layer nodes to be too large. It had the same problem as the initial version, even more severe, as shown in the following image:
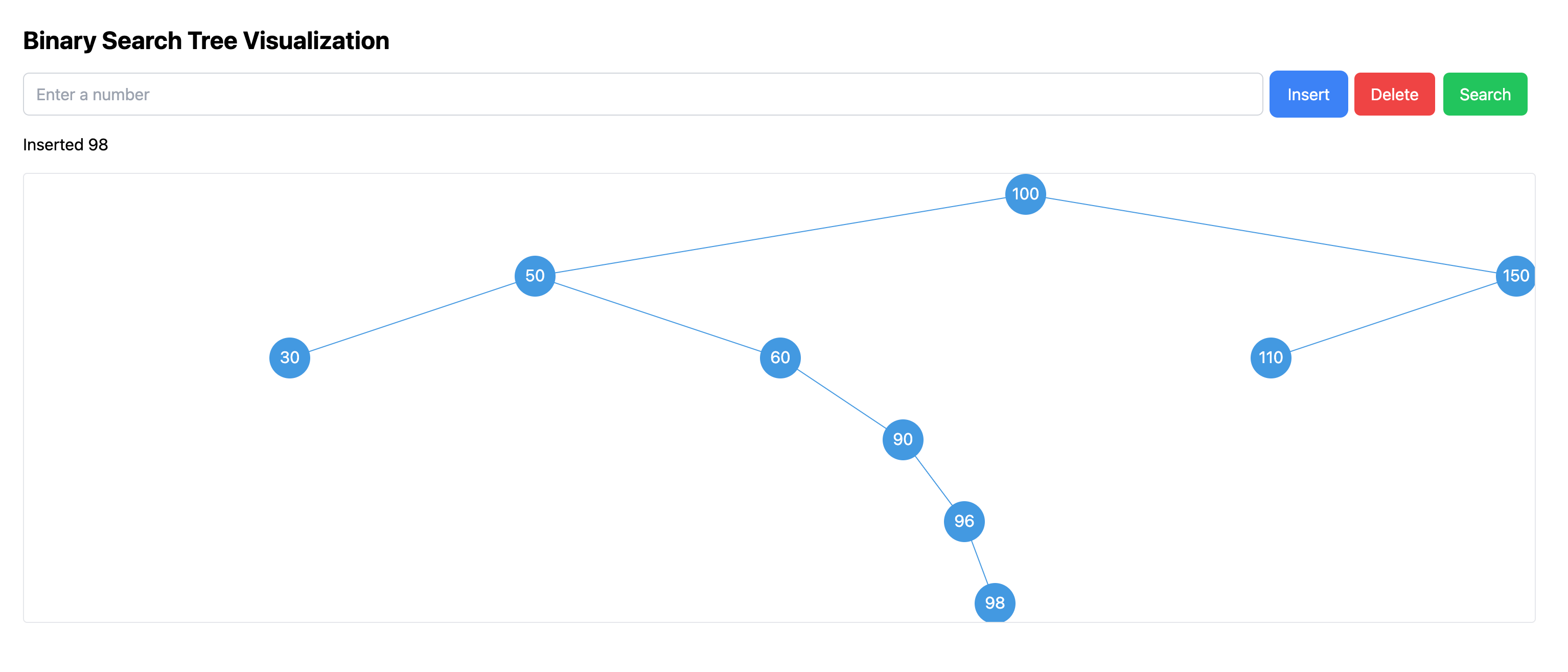
So I directly prompted it to make the spacing between each layer not too large, to make the layout more compact, and to ensure that nodes on the same level do not overlap. This resulted in the following:

This was compact, but the node distribution was problematic, with incorrect positions for left and right subtree nodes. After several attempts, my own thinking gradually became clearer. We want the tree layout to be as compact as possible while avoiding node intersections and overlaps. To achieve this, we only need to satisfy:
- All child nodes of each node must be to the right of all left sibling nodes.
- All child nodes of each node must be to the left of all right sibling nodes.
In other words, on the same level, all smaller nodes must be to the left of larger nodes, without overlaps or intersections. After figuring out the algorithm, I briefly described it to Claude 3.5, which quickly provided an implementation approach. The overall changes were as follows:
- New layout algorithm: The _updateLayout method now uses a new algorithm to allocate node coordinates.
- Node counting: Introduced the getNodeCount function to calculate the number of nodes in each subtree, helping to allocate space more accurately.
- Recursive coordinate assignment: The assignCoordinates function recursively assigns coordinates to each node, ensuring that the left subtree is always to the left of the right subtree.
- Dynamic space allocation: Each node's position is dynamically calculated based on the number of nodes in its left and right subtrees, ensuring a more even distribution.
- Level alignment: Nodes on the same level have the same y-coordinate, ensuring horizontal alignment.
- Avoiding intersections: By calculating the relative position of each node, it ensures that nodes on the same level are sorted from left to right by size, avoiding intersection issues.
Below is an image of the layout effect. You can see that with many nodes, the overall layout is relatively compact and meets the previous requirements.
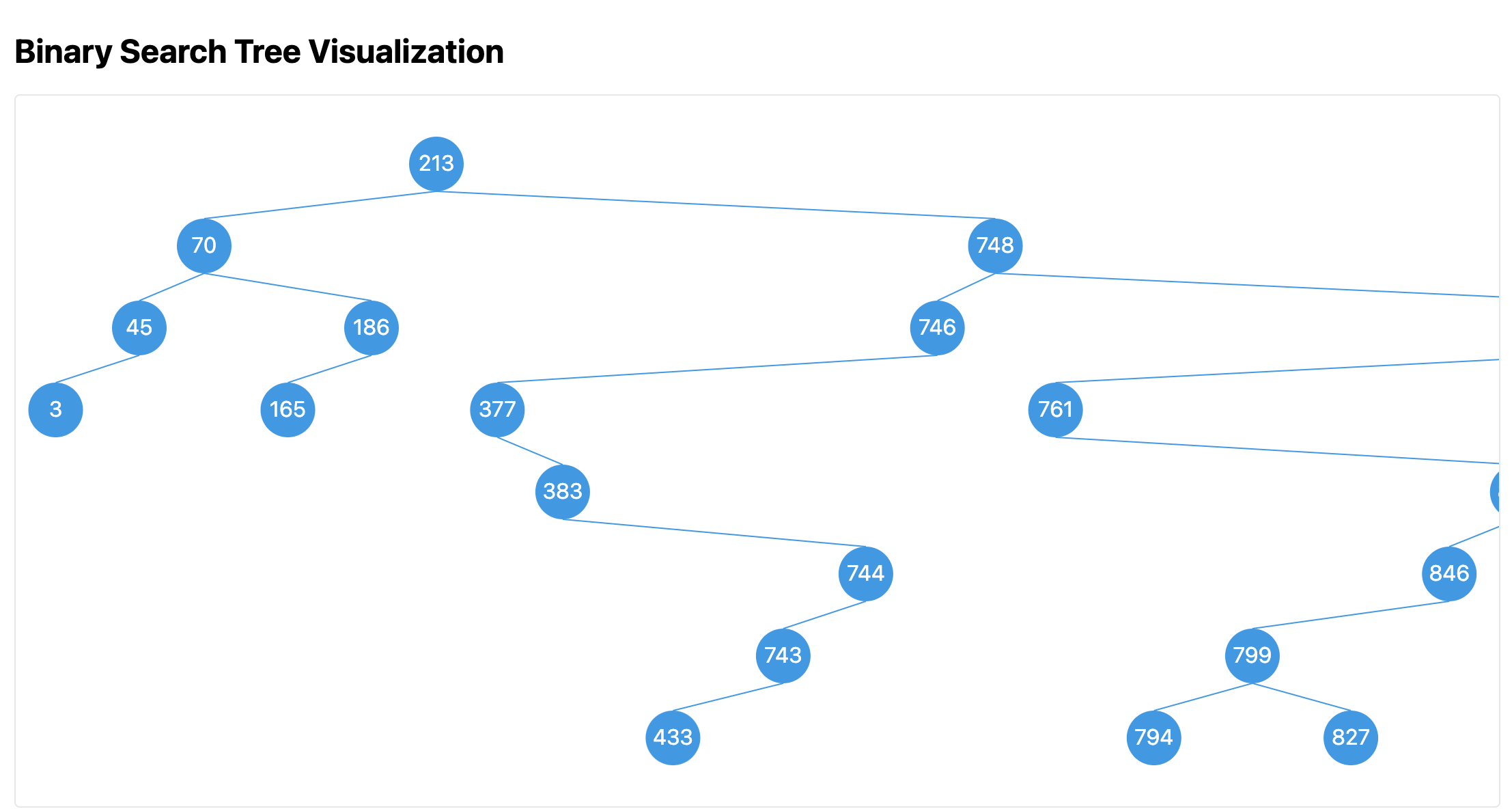
Interface Optimization
With the binary search tree layout problem solved, we moved on to optimizing the interface. Currently, it's quite simple, only allowing input of numbers for inserting, deleting, and searching nodes. However, inserting nodes one by one can be cumbersome, so we can support a more convenient method for initializing nodes. Considering the performance differences of binary search trees under sequential and random insertions, we can support two initialization methods. At the same time, to keep the overall page layout consistent with other visualization tools, we also adjusted the layout of the settings section.
Since the previous chat context was already quite long, to avoid consuming Claude 3.5's quota more quickly:
Your limit gets used up faster with longer conversations, notably with large attachments. For example, if you upload a copy of The Great Gatsby, you may only be able to send 15 messages in that conversation within 5 hours, as each time you send a message, Claude "re-reads" the entire conversation, including any large attachments. Ref: https://support.anthropic.com/en/articles/8324991-about-claude-pro-usage
I started a new dialogue with Claude, directly copying the complete code from before, and then provided the following prompt:
This is the implementation of the binary search tree visualization. Help me optimize it:
- Divide into two areas. On large screens, divide left and right, with the display area on the left occupying 3/4, and the settings area on the right occupying 1/4, with each button on a separate line. On small screens, divide top and bottom, with settings on top and display below;
- Support setting the initial number of nodes, with a maximum of 50. Then support selecting the initialization method, with options for random initialization and sequential initialization.
Claude then refactored the interface part and added initialization buttons. However, the initial version of the SVG tree part didn't support scrolling, and nodes might exceed the screen. After prompting again, scrollbars were added. The final effect is as follows, with 15 nodes initialized sequentially:
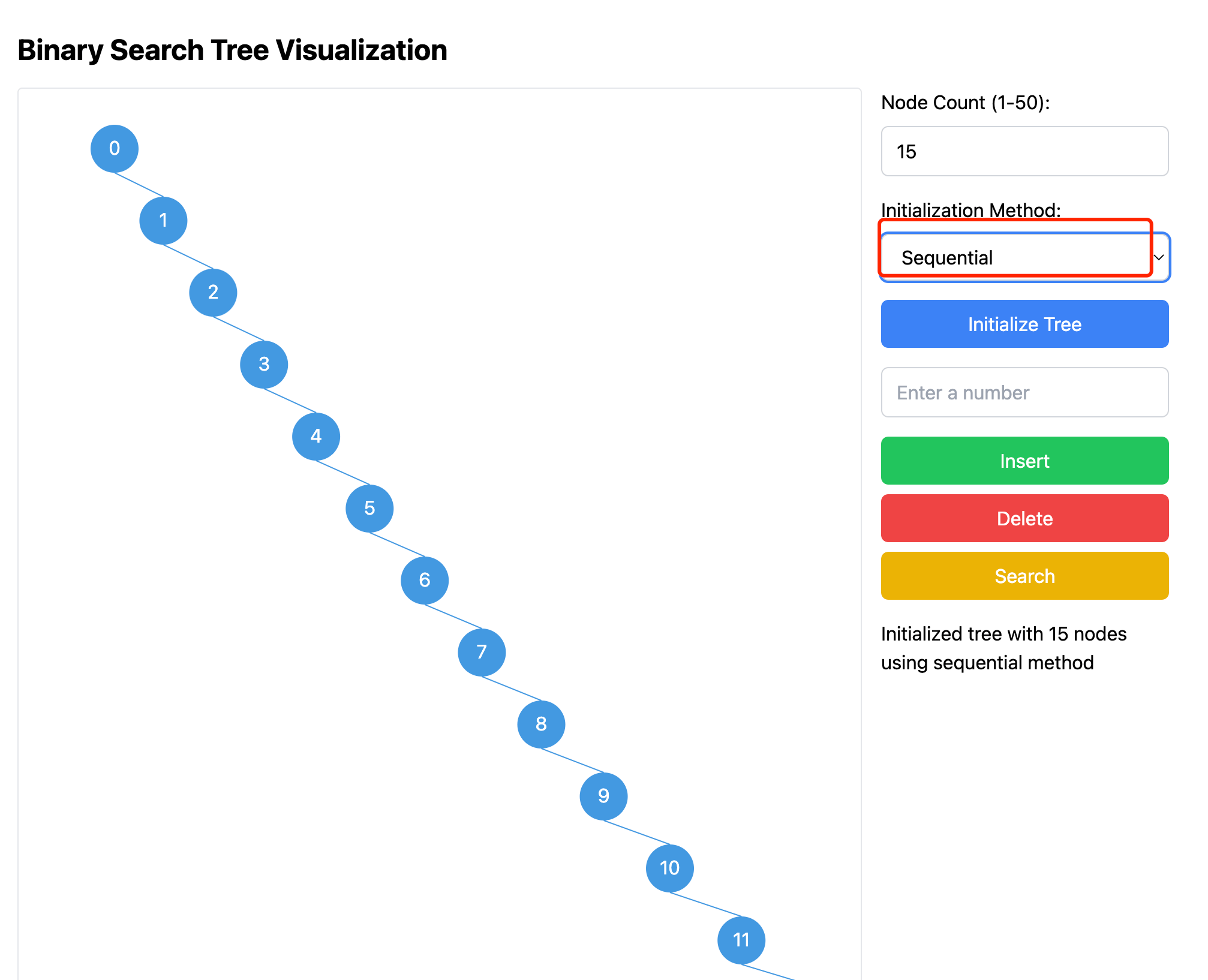
Adding Animation
Next, I wanted to add some animation demonstrations to the entire visualization, such as demonstrating the entire search path and then highlighting it when inserting a node. Visualization animations are actually one of the more challenging parts for AI to implement, possibly because the requirements themselves are difficult to describe. Here, I started a new dialogue to avoid the previous conversation becoming too long and affecting Claude's performance. After restarting, I uploaded all the current code as reference, and then used the following prompt:
This is a binary search tree visualization that currently supports tree layout and insert, delete, and search operations. Now I want to optimize the visualization process to support displaying the process of insertion, deletion, and search.
- During insertion, highlight each node on the search path in sequence. Only remove the highlight after all nodes are inserted.
- During search, highlight each node on the search path in sequence. Until the search is successful or fails.
- During deletion, highlight each node on the search path in sequence. Then delete the node and adjust the tree structure. The changes should be minimal, and the code should be flexible.
The provided code had various issues. The initial version highlighted the entire path at once and showed the newly inserted node. There were errors during deletion. After several rounds of dialogue, various small issues were gradually fixed. Then, coincidentally seeing that cursor was quite popular, I tried using cursor for subsequent development. I attempted to let Cursor help me fix small bugs, such as when deleting a node, the current version still shows successful deletion even if the node doesn't exist. So I directly asked the AI to make changes, as shown in the following image:
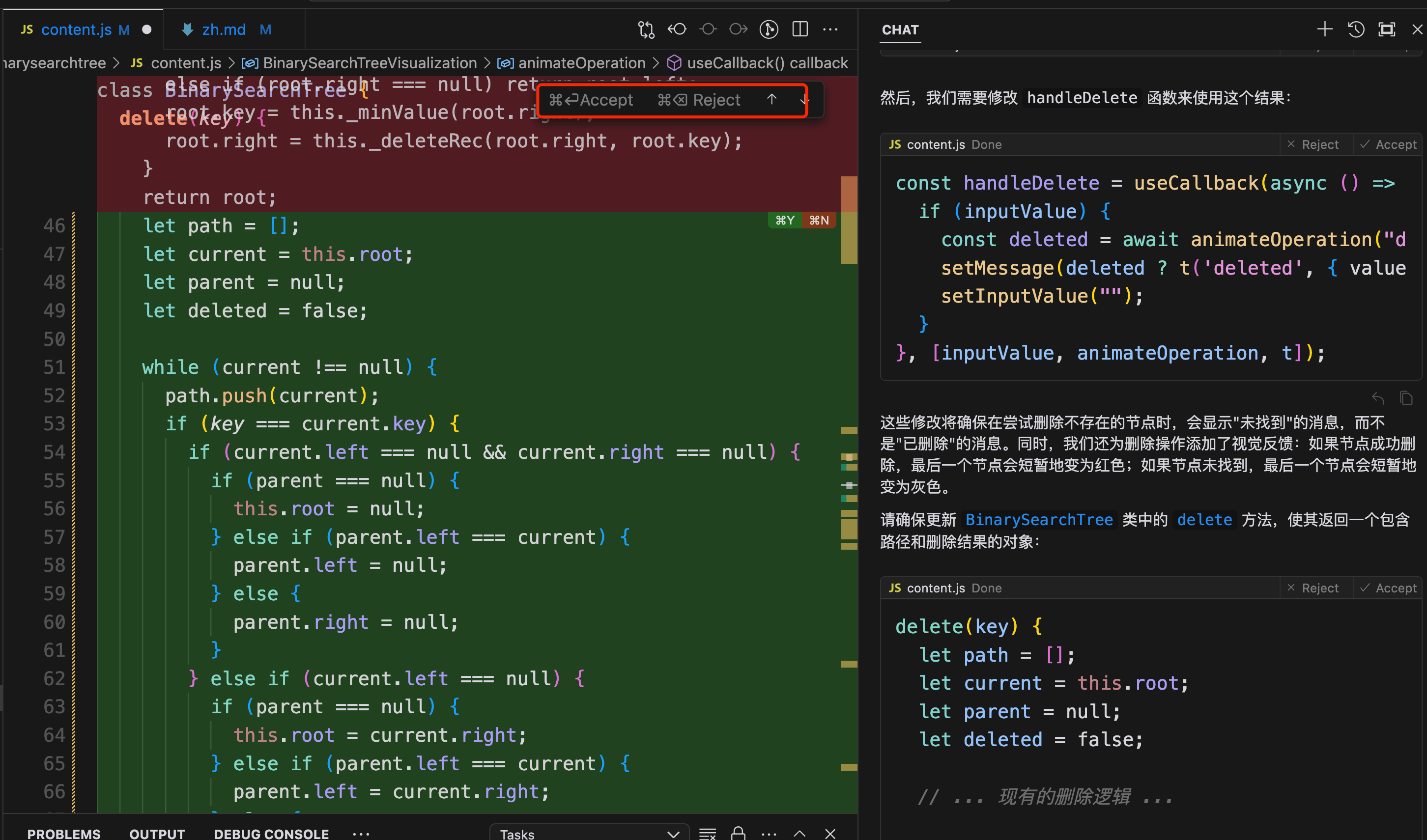
The AI provided all the changes, and I first reviewed them and then directly applied them. Before using cursor, I had to manually find the changed parts from Claude and paste them over. In comparison, with cursor, I only need to look at the code diff and decide whether to adopt it. Then I just need to test the functionality myself, haha, I feel like I've become a tester now.
Internationalization Support
At this point, the basic functionality was mostly complete, and I wanted to add internationalization support, as the entire site already supports Chinese and English. After opening content.js, I directly initiated a chat, asking cursor to use Claude 3.5 to help me support translation.
Modify the entire file to support translation internationalization where text was previously hardcoded. Finally, modify the translation files zh.json and en.json
The AI-generated part was not much different from directly using Claude, mainly modifying the hardcoded text in the code and adding translation files. However, the power of cursor lies in being able to click Apply, which directly patches the code changes into the file. I only needed to review and confirm along the way.
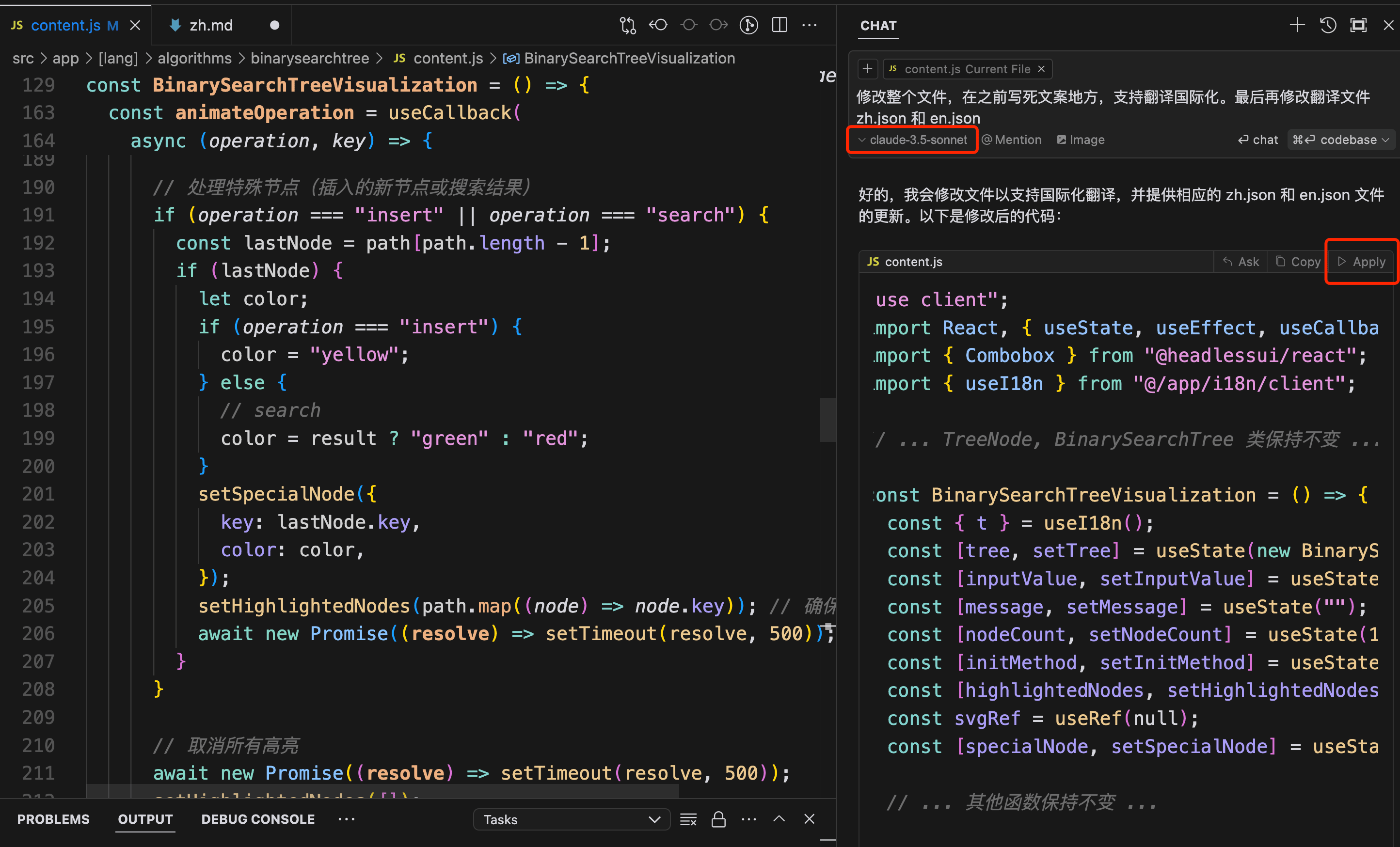
However, the translation json files currently can't be automatically added to en.json and zh.json according to my previous style, still requiring some manual editing, which is a slight imperfection.
Testing
To avoid manual testing after each subsequent change, I decided to try letting AI help me write test cases. I hadn't written frontend test cases before and didn't know how to test UI components. Let's see how AI answers, with a simple prompt:
How can I provide complete and rigorous tests for this binary search tree visualization page?
Claude 3.4 immediately provided detailed ideas and implementation code:
Unit tests: Test various methods of the BinarySearchTree class and TreeNode class. Component tests: Test the UI display of components. Snapshot tests: Create snapshots of components to detect unexpected UI changes. This sounds a bit advanced. End-to-end tests: Use Cypress or Playwright for end-to-end testing, simulating user interactions and visual checks. Performance tests: Use React performance tools or Lighthouse for performance testing, especially for rendering large trees. (No code was provided for this, but I could have asked further if I wanted to pursue it)
It's a pretty good response, although I haven't had time to look closely at his test cases yet. I'll write a separate article later on how to add test cases to the visualization tools on this site.
Conclusion
Thanks to Claude 3.5's powerful understanding and programming capabilities, the entire implementation process was quite smooth. However, there were also quite a few pitfalls along the way. For example, the initial tree layout had incorrect thinking, leading to poor results. There were also some small bugs that needed constant fixing, such as when deleting a node, the current version still shows successful deletion even if the node doesn't exist.
When using Github copilot before, the coding process could only complete downwards, not fully utilizing the advantages of large models. Now that I've tried cursor, I've found that it can indeed improve development efficiency significantly, focusing on code suggestions, with AI-modified code automatically updating in the editor, which is really comfortable.