Loading hash ring...
一致性哈希环是一种特殊的哈希算法,主要用于分布式系统中数据的分配和负载均衡。它将哈希值空间映射到一个环形结构上,范围从 0 到 2^32-1。通过这种方式,我们可以更好地处理节点的添加和删除,同时最小化数据迁移。
一致性哈希环基本原理
一致性哈希环的核心思想是将整个哈希值空间想象成一个首尾相连的环形结构,这个环的范围从 0 到 2^32-1。在这个环形空间中,我们首先需要将服务器节点分布到环上。每个服务器节点都会通过哈希函数计算得到一个哈希值,这个哈希值就决定了该服务器在环上的位置。
当我们需要存储或查找数据时,同样会使用哈希函数计算数据的哈希值,从而确定数据在环上的位置。确定好数据的位置后,沿着环顺时针方向查找,遇到的第一个服务器节点就是该数据的存储位置。这种机制确保了数据和服务器之间的映射关系稳定且可预测。
这种设计的优雅之处在于,当需要添加或删除服务器节点时,只会影响到环上相邻节点之间的数据分布,而不会导致全局的数据重新分配。这大大减少了在分布式系统扩容或节点失效时的数据迁移成本。
为什么需要虚拟节点?
在实际应用中,基本的哈希环存在一个明显的问题:当服务器节点数量较少时,容易出现数据分布不均匀的情况。这是因为哈希函数的结果在环上的分布可能并不均匀,导致某些服务器节点需要处理更多的数据,而其他节点则相对空闲。这种数据倾斜问题会严重影响系统的性能和可用性。
如下图所示,在只有 10 个物理节点且没有使用虚拟节点的情况下,我们可以明显观察到数据分布的不均匀性。图中每个环形段代表一个节点负责的数据范围,不同颜色的节点对应的数据占比差异很大。比如绿色节点负责了 176 个键,而橙色节点上没有数据,这种巨大的差异会导致绿色节点负载过重,而橙色节点资源闲置,整个系统的资源利用效率低下。
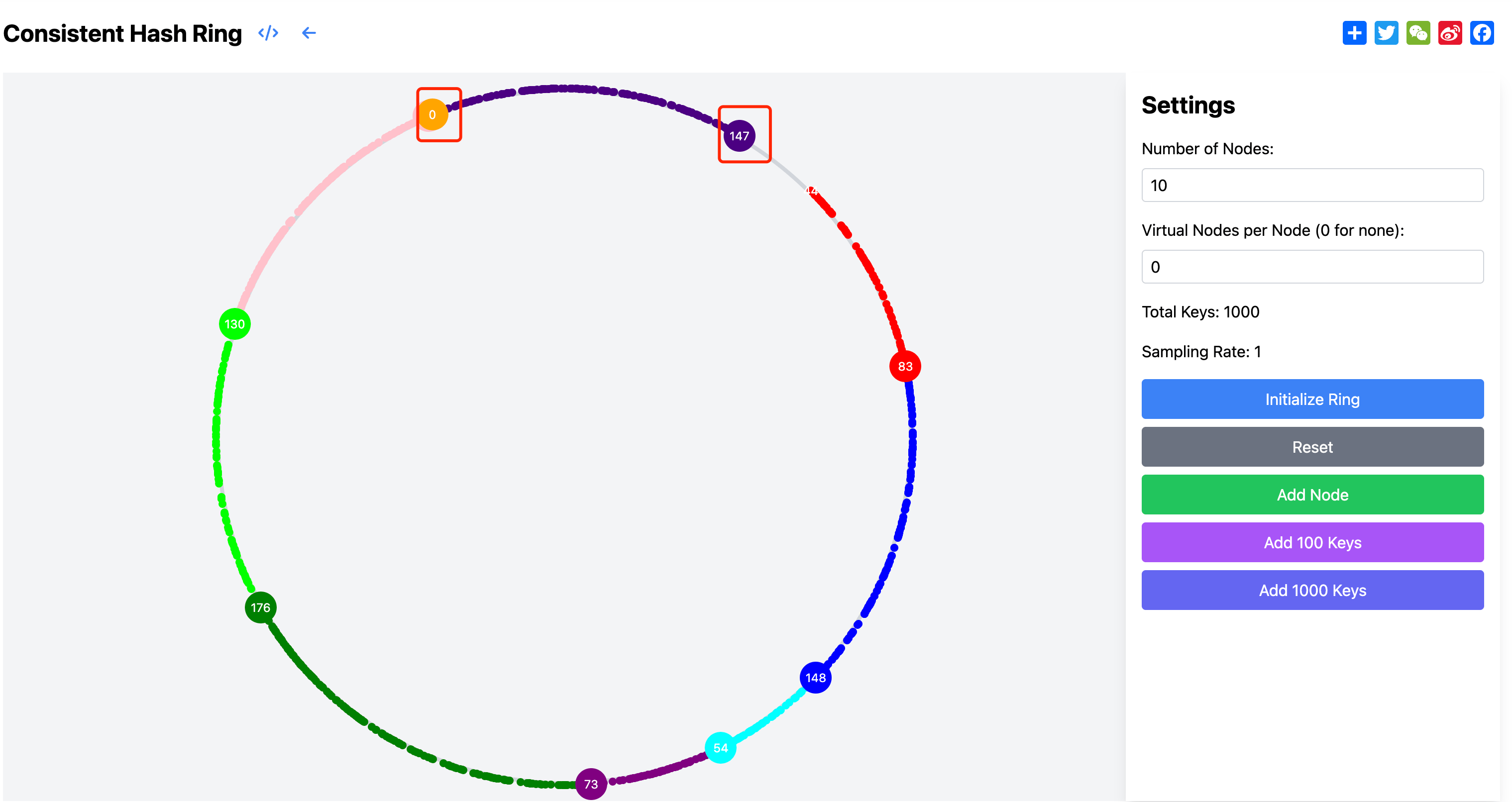
这种不均匀分布的根本原因在于,当节点数量较少时,哈希函数计算出的位置可能会在环上分布得不够均匀,导致某些节点之间的间隔较大,而另一些节点之间的间隔较小。较大的间隔意味着该节点需要负责更多的数据范围,从而处理更多的请求。这个问题在后面会通过引入虚拟节点的机制来解决。
虚拟节点的工作原理
虚拟节点的核心思想是将每个物理节点虚拟化成多个虚拟节点。具体来说,系统会为每个实际的服务器节点创建多个虚拟副本,每个虚拟副本都会在哈希环上占据一个位置。这些虚拟节点虽然在环上占据不同的位置,但它们最终都会映射到同一个实际的物理服务器上。
通过引入虚拟节点,我们显著增加了环上节点的数量,使得数据分布更加均匀。例如,如果我们为每个物理节点创建 100 个虚拟节点,那么在只有 4 个物理节点的情况下,环上实际上会有 400 个分布点。这种方式能够有效地平衡数据负载,减少数据倾斜的风险。同时,虚拟节点的数量是可以根据实际需求进行调整的,这提供了更灵活的负载均衡能力。
一致性哈希环可视化操作
在我们的交互式可视化工具中,你可以通过多种操作来深入理解一致性哈希环的工作原理和数据分布特性。
节点管理操作
通过添加和删除节点,你可以观察一致性哈希环如何动态调整数据分布。点击界面上的"添加节点"按钮,系统会自动在环上的随机位置处添加一个新的服务器节点。每个节点都有一个唯一的标识符和对应的颜色标记,方便观察和区分。
当你需要移除某个节点时,只需点击该节点,然后在弹出的弹窗上点击删除按钮即可。这个过程会直观地展示数据是如何重新分配的,以及为什么一致性哈希算法能够最小化节点变更带来的数据迁移。
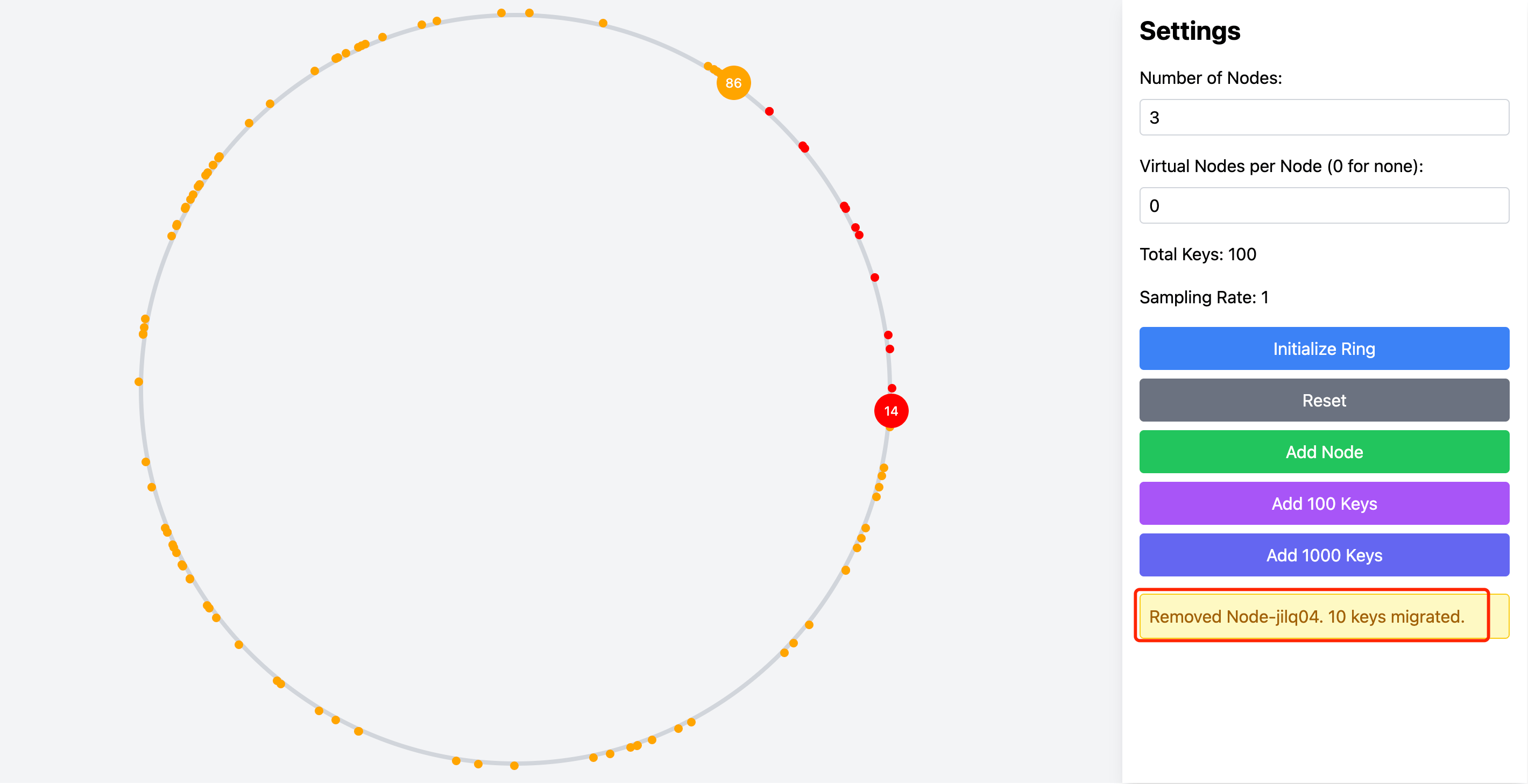
虚拟节点配置
虚拟节点是提高数据分布均匀性的关键机制。在界面上,你可以调整每个物理节点对应的虚拟节点数量。默认情况下,每个物理节点没有虚拟节点,你可以通过设置这个数值来观察其影响。当你调整虚拟节点数量时,可以实时观察到环上节点分布的变化,以及这些变化如何影响数据的分配。
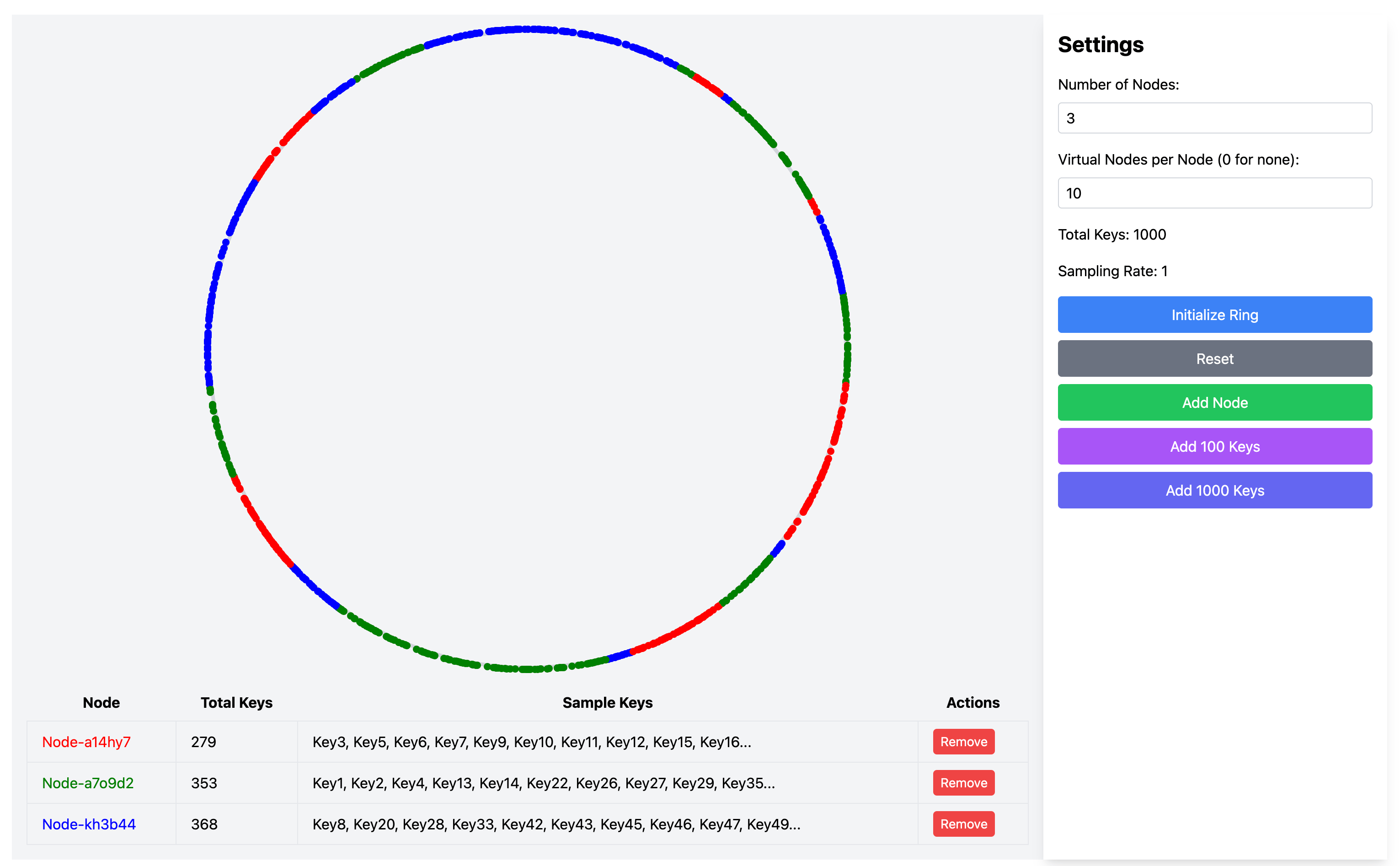
在可视化界面中,每个虚拟节点都会以较小的圆点显示在环上,并通过相同的颜色标识其所属的物理节点。例如,如果设置虚拟节点数量为 10,那么每个物理节点都会在环上产生 10 个虚拟节点,这些虚拟节点会均匀分布在环的不同位置。当有数据需要存储时,系统会先找到数据对应位置的下一个节点(可能是虚拟节点),然后将数据存储到该虚拟节点对应的物理节点上。
通过增加虚拟节点,我们可以明显观察到数据分布变得更加均匀。在没有虚拟节点时,可能会出现某些物理节点负载过重的情况,而增加虚拟节点后,每个物理节点的负载会趋于平衡。如下图所示,通过调整虚拟节点的数量,原本不均匀的数据分布(部分节点占比明显偏高)变得更加均衡,各个物理节点的数据占比趋于一致。
实时反馈
所有的操作都会得到实时的视觉反馈。当你进行节点添加、删除或调整虚拟节点数量时,可以观察到:
- 数据分布比例的实时变化
- 节点负责范围的动态调整
- 虚拟节点在环上的分布情况
- 数据迁移的过程和影响范围
通过这些交互操作和可视化效果,你可以更好地理解一致性哈希环的工作原理,以及虚拟节点如何帮助改善数据分布。建议多尝试不同的配置组合,观察系统的行为变化,这将帮助你更深入地理解这个重要的分布式系统概念。
一致性哈希环优点
一致性哈希环最显著的优势是其出色的扩展性。系统可以根据需求动态地添加或删除节点,而不会导致大规模的数据迁移。当新增或移除节点时,只有相邻节点之间的数据需要重新分配,这大大减少了系统扩容或缩容时的开销。这种特性使得系统能够灵活应对负载变化,轻松实现横向扩展。
在负载均衡方面,一致性哈希环通过虚拟节点技术实现了更均匀的数据分布。每个物理节点可以在环上拥有多个虚拟节点,这种机制显著降低了数据倾斜的风险。即使某些区域的数据访问较为密集,通过合理配置虚拟节点数量,也能确保负载相对均衡地分布在各个物理节点上。
此外,一致性哈希环还具有很高的可用性。当某个节点发生故障时,只有该节点负责的数据需要重新分配到其他节点,不会影响到系统的整体运行。系统可以快速进行故障恢复,将受影响的数据重新分配到环上的其他节点,从而保证服务的连续性。
一致性哈希环缺点
然而,一致性哈希环也存在一些局限性。首先,数据分布的均匀性很大程度上依赖于所选用的哈希函数。如果哈希函数的质量不佳,可能会导致数据在环上分布不均匀,影响负载均衡效果。因此,在实际应用中需要精心选择合适的哈希函数,这往往需要在性能和均匀性之间做出权衡。
虚拟节点机制虽然改善了数据分布,但也增加了系统的复杂度。系统需要维护大量虚拟节点与实际物理节点之间的映射关系,这不仅增加了内存开销,还会影响查找效率。在大规模分布式系统中,这种额外的开销需要在系统设计时认真考虑。
另外,初始节点数量的设置也是一个重要考虑因素。当系统启动时节点数量过少,即使使用了虚拟节点机制,也可能出现数据分布不均的情况。这要求在系统初始部署时就需要合理规划节点数量,并制定相应的扩容策略。
一致性哈希环应用场景
一致性哈希环在分布式系统中有着广泛的应用。在分布式缓存系统中,如 Memcached,它被用来确定缓存数据应该存储在哪个节点上。通过一致性哈希环,系统可以高效地定位数据位置,并在节点发生变化时最小化数据迁移。
在分布式存储系统中,一致性哈希环用于数据分片和负载均衡。它能够确保数据均匀地分布在各个存储节点上,同时在节点扩容或故障时保持系统的稳定性。
对于负载均衡器来说,一致性哈希环提供了一种有效的请求分发机制。它可以根据请求的特征将流量均匀地分配到不同的后端服务器,并且在服务器数量发生变化时,只需要重新分配少量请求。
在分布式数据库系统中,一致性哈希环常用于数据分片策略的实现。它可以帮助数据库系统将数据均匀地分布在多个分片上,并在分片数量变化时最小化数据迁移的影响。