布隆过滤器由 Burton Howard Bloom 在1970年提出,是一种空间效率很高的概率型数据结构。它的主要用途是快速判断一个元素是否属于一个集合。布隆过滤器可以告诉我们 "某个元素一定不存在集合中" 或者 "某个元素可能存在集合中"。
布隆过滤器的核心组件是一个位数组和多个哈希函数。在初始状态下,位数组中的所有位都被设置为0。当需要添加一个元素时,系统会使用多个不同的哈希函数对该元素进行处理。每个哈希函数都会将元素映射到位数组中的某个位置。这些被映射到的位置随后会被设置为1。通过使用多个哈希函数,每个元素都会在位数组中标记多个位置。
当需要查询一个元素是否存在时,系统会使用相同的哈希函数对查询元素进行处理,得到对应的位置。然后检查位数组中这些位置的值。如果发现任何一个位置的值为0,那么可以确定该元素一定不在集合中,因为如果元素曾经被添加过,这些位置应该都是1。然而,如果所有对应位置的值都是1,我们只能说该元素可能存在于集合中,因为这些位置的1可能是由其他元素设置的。这就是布隆过滤器的一个特性:它可能会产生假阳性(误报),但不会产生假阴性(漏报)。
布隆过滤器可视化页面指南
在使用布隆过滤器可视化工具之前,您需要先配置两个重要参数。首先是预期键数量(Predicted Key Count),这个参数用于设置您预计要存储的元素数量,可以在1到5000之间进行调整。预期键数量直接影响位数组的大小,合理的设置可以帮助优化空间使用和降低误判率。
另一个重要参数是哈希函数数量(Hash Function Count),您可以设置使用1到30个不同的哈希函数。哈希函数的数量会直接影响布隆过滤器的准确率和性能表现。通常来说,使用更多的哈希函数可以降低假阳性的概率,但同时也会增加计算开销。
布隆过滤器插入、查找
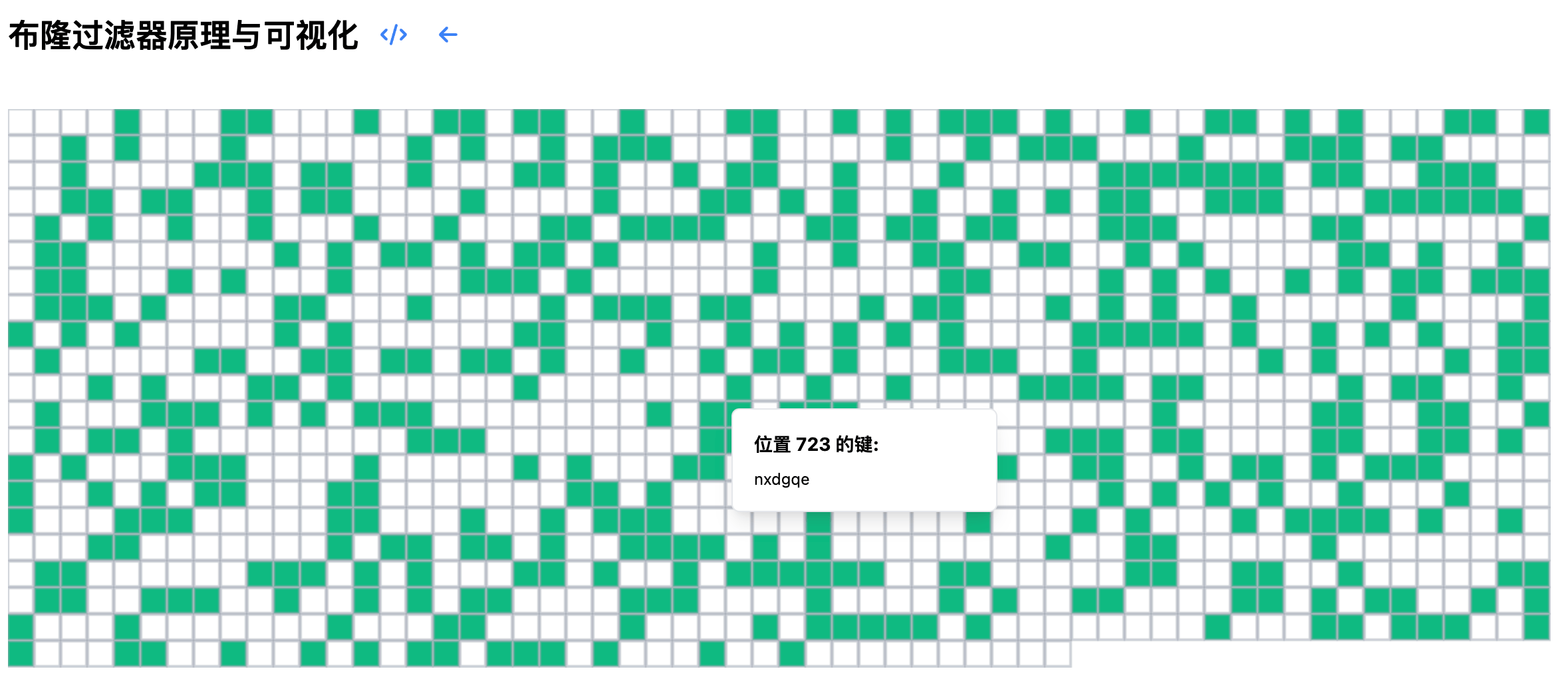
本工具提供了多种操作布隆过滤器的方式。您可以通过输入框添加单个元素,只需在输入框中输入想要添加的字符串,然后点击"添加"按钮,系统就会将该元素加入过滤器中。添加成功后,您可以在位数组上观察到对应位置被标记为绿色,直观地展示了元素的存储位置。
对于元素查询,您可以在输入框中输入要查询的字符串,然后点击"搜索"按钮。系统会用不同的颜色标记查询结果:橙色标记表示该元素可能存在于集合中,而红色标记则明确指示该元素一定不在集合中。

为了方便测试和演示,系统还提供了批量操作功能。可以选择一次性添加10个或100个随机键,这对于观察布隆过滤器在大量数据下的表现非常有帮助。如果您想重新开始测试,可以使用"重置"按钮将过滤器恢复到初始状态。
布隆过滤器可视化设计
位数组的显示采用了直观的颜色编码系统。已经设置为1的位置会以绿色显示,而未设置的位置(值为0)则保持白色。当您进行查询操作时,相关的位置会显示数字标记,帮助您理解哈希函数将查询元素映射到了哪些位置。
本工具还提供了丰富的交互功能。当您的鼠标悬停在已设置的位置上时,可以查看到影响该位置的所有键的详细信息。如果您想要仔细研究某个位置的信息,可以通过点击该位置来固定显示这些详细信息。这些交互特性能帮助您更好地理解布隆过滤器的工作原理和数据分布情况。
需要注意的是,这些键的详细信息仅用于演示目的,是本可视化工具额外存储的数据。在实际的布隆过滤器实现中,并不会存储这些原始键信息,这也是布隆过滤器能够实现高空间效率的原因之一。这些交互特性的目的是帮助您更好地理解布隆过滤器的工作原理和数据分布情况。
布隆过滤器的优缺点
布隆过滤器最显著的优势是其极高的空间效率,它只需要很小的空间就能存储大量数据。这是因为它不存储元素本身,而只存储元素的指纹信息。在查询性能方面,布隆过滤器表现出色,其时间复杂度仅为 O(k),其中 k 是哈希函数的个数,这意味着查询速度与存储的数据量无关。
另一个重要优点是布隆过滤器支持动态添加元素。由于其特殊的数据结构设计,新元素可以随时被添加到过滤器中,而不需要重建整个数据结构。这种特性使其特别适合处理大规模数据集,尤其是在数据量持续增长的场景中。
布隆过滤器的主要缺点是存在误判的可能性。虽然它能够准确地判断一个元素一定不存在,但当它判断元素存在时,实际上只能说明该元素可能存在。这种假阳性(false positive)的特性在某些应用场景中可能会造成困扰。
另一个显著的限制是布隆过滤器不支持删除操作。这是因为一个位置的比特位可能被多个元素共同使用,删除一个元素可能会影响到其他元素的判断。此外,在使用布隆过滤器时,需要预先估计数据量的大小。如果预估的数据量过小,会导致位数组过快地被填充,从而增加误判率。
最后,布隆过滤器无法获取实际存储的元素。这是因为它只存储元素的指纹信息,而不保存原始数据。这个特性虽然帮助节省了空间,但也限制了它的使用场景。
应用场景
布隆过滤器在网络爬虫中被广泛用于URL去重。当爬虫需要处理数以亿计的URL时,布隆过滤器可以高效地判断一个URL是否已经被访问过,从而避免重复抓取。在垃圾邮件过滤系统中,布隆过滤器可以用来快速检查邮件地址是否在黑名单中,有效提高过滤效率。
在数据库系统中,布隆过滤器常被用于缓存穿透的防护。当查询一个不存在的数据时,布隆过滤器可以快速判断该数据是否可能存在,避免对数据库进行无谓的访问。对于大型数据库的查询优化,布隆过滤器可以作为一个预过滤器,在进行复杂的数据库查询之前,先快速排除一定不存在的情况,从而提高查询效率。