The Bloom filter, proposed by Burton Howard Bloom in 1970, is a space-efficient probabilistic data structure. Its main purpose is to quickly determine whether an element belongs to a set. A Bloom filter can tell us that "an element definitely does not exist in the set" or "an element may exist in the set".
The core components of a Bloom filter are a bit array and multiple hash functions. Initially, all bits in the array are set to 0. When adding an element, the system processes it using multiple different hash functions. Each hash function maps the element to a position in the bit array. These mapped positions are then set to 1. By using multiple hash functions, each element marks multiple positions in the bit array.
When querying whether an element exists, the system processes the query element using the same hash functions to obtain the corresponding positions. It then checks the values at these positions in the bit array. If any position has a value of 0, we can definitively determine that the element is not in the set, because if the element had been added before, all these positions would be 1. However, if all corresponding positions are 1, we can only say that the element might exist in the set, as these 1s could have been set by other elements. This is a key characteristic of Bloom filters: they may produce false positives (false alarms) but never false negatives (missed detections).
Bloom Filter Visualization Guide
Before using the Bloom filter visualization tool, you need to configure two important parameters. First is the Predicted Key Count, which sets the number of elements you expect to store, adjustable between 1 and 5000. The predicted key count directly affects the size of the bit array, and appropriate settings help optimize space usage and reduce false positive rates.
The other important parameter is the Hash Function Count, where you can set between 1 to 30 different hash functions. The number of hash functions directly affects the accuracy and performance of the Bloom filter. Generally, using more hash functions can reduce the probability of false positives but also increases computational overhead.
Bloom Filter Insertion and Search
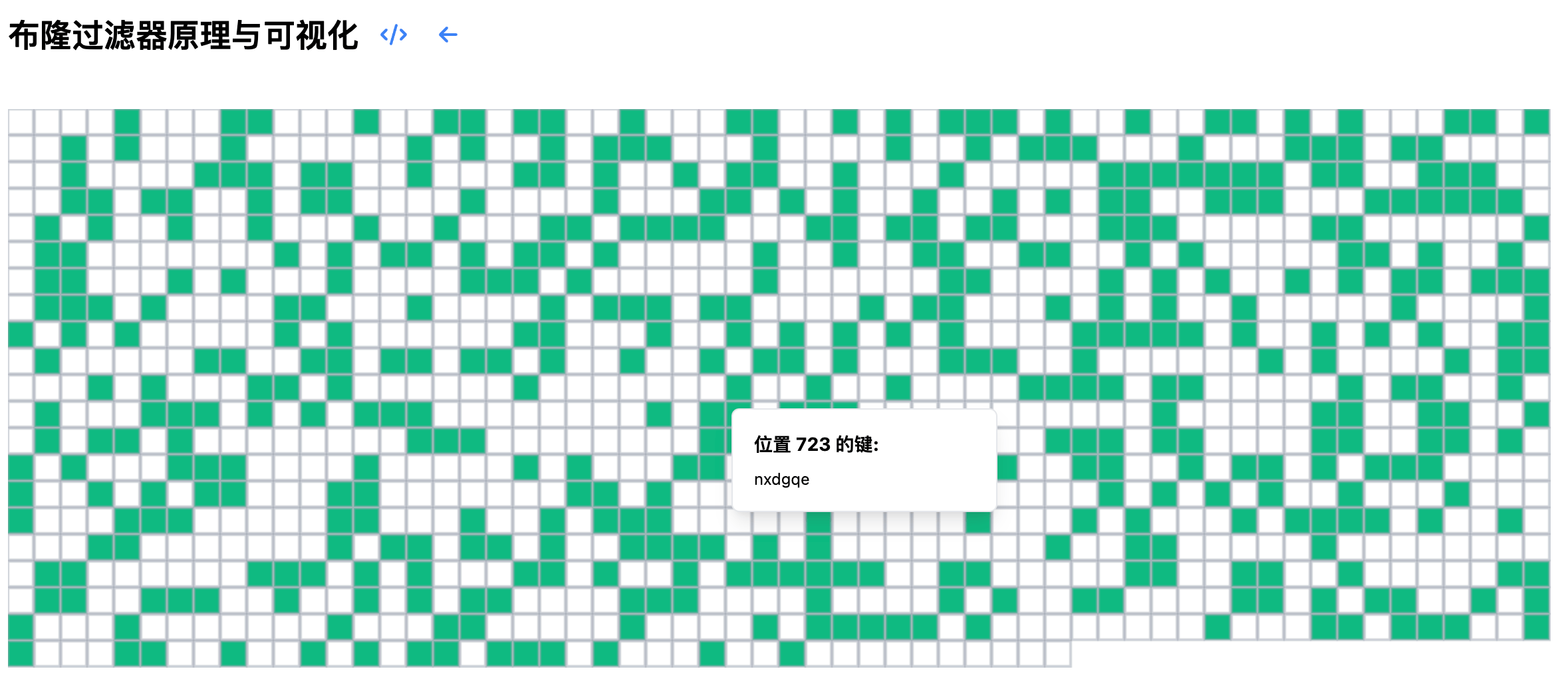
The tool provides various ways to operate the Bloom filter. You can add individual elements through the input box - simply enter the desired string and click the "Add" button to add it to the filter. After successful addition, you can observe the corresponding positions marked in green on the bit array, visually showing the element's storage locations.
For element queries, enter the string you want to query in the input box and click the "Search" button. The system marks query results with different colors: orange indicates the element might exist in the set, while red definitively indicates the element is not in the set.

For testing convenience, the system also provides batch operations. You can add 10 or 100 random keys at once, which is helpful for observing how the Bloom filter performs with large amounts of data. If you want to start fresh, you can use the "Reset" button to restore the filter to its initial state.
Bloom Filter Visualization Design
The bit array display uses an intuitive color coding system. Positions set to 1 are shown in green, while unset positions (0) remain white. During query operations, relevant positions display numerical markers, helping you understand how hash functions map query elements to different positions.
The tool also offers rich interactive features. When you hover your mouse over set positions, you can see detailed information about all keys affecting that position. If you want to study a position's information carefully, you can click on it to pin the detailed information display. These interactive features help you better understand the working principles and data distribution of the Bloom filter.
Note that these detailed key information are stored additionally for demonstration purposes in this visualization tool. In actual Bloom filter implementations, these original key information are not stored, which is one reason why Bloom filters achieve high space efficiency. These interactive features are designed to help you better understand how Bloom filters work and how data is distributed.
Advantages and Disadvantages of Bloom Filters
The most significant advantage of Bloom filters is their extremely high space efficiency, requiring very little space to store large amounts of data. This is because they don't store the elements themselves, but only their fingerprint information. In terms of query performance, Bloom filters excel with a time complexity of O(k), where k is the number of hash functions, meaning query speed is independent of the amount of stored data.
Another important advantage is that Bloom filters support dynamic element addition. Due to their special data structure design, new elements can be added to the filter at any time without rebuilding the entire structure. This feature makes them particularly suitable for handling large-scale datasets, especially in scenarios with continuously growing data.
The main disadvantage of Bloom filters is the possibility of false judgments. While they can accurately determine that an element definitely doesn't exist, when they indicate an element exists, it only means the element might exist. This false positive characteristic can be problematic in certain application scenarios.
Another significant limitation is that Bloom filters don't support deletion operations. This is because a bit position might be shared by multiple elements, and deleting one element could affect the judgment of other elements. Additionally, when using a Bloom filter, you need to estimate the data volume in advance. If the estimated data volume is too small, the bit array will fill up too quickly, increasing the false positive rate.
Finally, Bloom filters cannot retrieve the actually stored elements. This is because they only store element fingerprint information, not the original data. While this feature helps save space, it also limits their use cases.
Application Scenarios
Bloom filters are widely used in web crawlers for URL deduplication. When crawlers need to process billions of URLs, Bloom filters can efficiently determine whether a URL has already been visited, avoiding duplicate crawling. In spam email filtering systems, Bloom filters can quickly check if an email address is on a blacklist, effectively improving filtering efficiency.
In database systems, Bloom filters are commonly used for cache penetration protection. When querying non-existent data, Bloom filters can quickly determine whether the data might exist, avoiding unnecessary database access. For large database query optimization, Bloom filters can serve as pre-filters, quickly ruling out definitely non-existent cases before performing complex database queries, thereby improving query efficiency.